| Python exemplarisch |
(Shoppinglisten) Recommender Systeme
(Filmempfehlungen) Klassifizierung
(KNN Algorithmus) Mustererkennung
(Ziffern) Regressionsanalyse
(Wiederverkaufswert) Clusteranalyse
(Voronoi-Diagramm) OneR-Algorithmus
(Wettervorhersage) Neuronale Netze
(In Vorbereitung)
Affinitätsanalysen
![]()
|
Alle Programme können von hier heruntergeladen werden. |
|
|
Problembeschreibung |
|
Beim Einkauf in einem Supermarkt aber auch über das Internet können die Kunden mehrere Produkte miteinander einkaufen. Es ist oft interessant, das Kundenverhalten zu studieren und herauszufinden, welche Produkte oft gemeinsam eingekauft werden. Dadurch können etwa Kunden gezielt beworben werden, indem ihnen beim Einkauf des einen Produkts der Kauf eines dazu affinen Produkts angeboten wird. Statt für Einkäufe in einem Supermarkt werden solche Informationen auch bei Bücherbestellungen im Online-Buchhandel oder beim Mieten von TV-Filmen gesammelt und gezielt ausgewertet. Wir betrachten exemplarisch 6 Produkte in einem Supermarkt für Lebensmittel: Brot (bread), Käse (cheese), Äpfel (apple), Bananen (banana), Teigwaren (pasta), Tomatensauce (sugo) An der Kasse werden die gekauften Produkte erfasst. Jeder Einkauf entspricht einem Datensatz, d.h. jede Person hat die Attribute (attributes): Brot (bread), Käse (cheese), Äpfel (apple), Bananen (banana), Teigwaren (pasta), Tomatensauce (sugo) mit je den Werten (values): 1 oder 0, je nachdem, ob sich das Produkt im Warenkorb befindet oder nicht. |
|
|
Erzeugung der Daten |
|
Zuerst erstellen wir in der Datei shopping.dat eine zufällige Datensammlung, die aber gewisse Tendenzen (typisch für Schweizer Personen) widerspiegelt. Die Werte der Attribute jedes Datensatzes werden komma-getrennt in eine Datei gespeichert (entsprechend des häufigsten Formats von csv-Dateien). Programm: [►] # CreatePurchases.py from random import randint datafile = "shopping.dat" nbSamples = 100 attributes = ["bread", "cheese", "apple", "banana", "pasta", "sugo"] nbAttributes = len(attributes) fOut = open(datafile, "w") for i in range(nbSamples): purchase = [0] * nbAttributes r = randint(0, 100) if r <= 25: # Swiss germans like bread and cheese purchase[0] = 1 purchase[1] = 1 elif r > 25 and r <= 40: # Swiss romands like fruits purchase[2] = 1 purchase[3] = 1 elif r > 40 and r <= 50: # Swiss italians like pasta with sugo purchase[4] = 1 purchase[5] = 1 else: # anybody else selects each item randomly for i in range(nbAttributes): r = randint(0, 100) if r < 50: purchase[i] = 1 purchaseStr = [str(e) for e in purchase] sample = ','.join(purchaseStr) fOut.write(sample + "\n") fOut.close() print nbSamples, "purchases saved." Bemerkungen: |
|
|
Affinität von Produkten |
|
Wir untersuchen die Wahrscheinlichkeiten bestimmter Affinitätsregeln: Falls jemand das Produkt A kauft, kauft er/sie auch das Produkt B. Beispiel: Falls jemand Pasta kauft, so kauft er/sie auch Sugo. Hier einige Begriffe: Unter der Prämisse (premise) versteht man die Aussage, dass jemand Pasta kauft, unter der Konklusion (conclusion) versteht man die Aussage, dass jemand dann auch Sugo kauft. Unter dem Support (support) versteht man die totale Zahl der Einkaufskörbe,bei denen die Prämisse erfüllt ist. Unter der Konfidenz (Confidence) versteht man die relative Anzahl, dass falls die Prämisse erfüllt ist, auch die Konklusion erfüllt ist. Programm: [►] # Shopping1.py dataFile = "shopping.dat" def loadIntData(fileName): ''' Reads data table from Ascii file with comma separated integers. Returns table as matrix in format [[row0], [row1], ...]. E.g. 1,2,3,4 -1,1,-1,1 20,50,100,600 returns [[1, 2, 3, 4], [-1, 1, -1, 1], [20, 50, 100, 600]] ''' try: fData = open(fileName, 'r') except: return [] out = [] for line in fData: li = [int(i) for i in line.split(',')] out.append(li) fData.close() return out # Read dataset with attributes: # bread, cheese, apple, banana, pasta, sugo X = loadIntData(dataFile) print "Rule: If a person buys pasta, they also buy sugo" # How many of the cases that a person bought pasta involved # the person purchasing sugo too? nbPastaPurchases = 0 ruleValid = 0 for sample in X: if sample[4] == 1: # This person bought pasta nbPastaPurchases += 1 if sample[5] == 1: # This person bought sugo too ruleValid += 1 print nbPastaPurchases, "cases of the pasta purchases were discovered." print ruleValid, "cases of the rule being valid were discovered" # The support is the (absolute) number of times the rule is discovered support = ruleValid # The confidence is the relative frequency the rule is discovered. confidence = ruleValid / nbPastaPurchases print "The support is", support, "and the confidence is", \ round(100 * confidence, 2), "percent" Typisches Resultat: |
|
|
Affinität zwischen allen Produkten |
|
Wir untersuchen die Wahrscheinlichkeiten bestimmter Affinitätsregeln: Falls jemand das Produkt A kauft, kauft er/sie auch das Produkt B. Beispiel: Falls jemand Pasta kauft, so kauft er/sie auch Sugo. Um einen Überblick über das Einkaufsverhalten zu erhalten, untersuchen wir alle möglichen Regeln. Es gibt offenbar 6 Prämissen, die man je mit 5 Konklusionen kombinieren kann, als 30 verschiedene Regeln. Die Attribute sollen durch einen Index 0...5 beschrieben sein. In einer 6x6-Tabelle (Matrix) fassen wir alle Support-Zahlen für die 30 Regeln zusammen.
Programm: [►] # Shopping2.py from pprint import pprint datafile = "shopping.dat" def printRule(): premiseName = attributes[premise] conclusionName = attributes[conclusion] print "Rule: If a person buys", premiseName, \ "they will also buy", conclusionName print " - Purchases with premise:", support[premise][premise] print " - Support:", support[premise][conclusion] print " - Confidence:", round(confidence[premise][conclusion], 2) print "" def loadIntData(fileName): fData = open(fileName, 'r') out = [] for line in fData: li = [int(i) for i in line.split(',')] out.append(li) fData.close() return out X = loadIntData(datafile) # Names of attributes attributes = ["bread", "cheese", "apple", "banana", "pasta", "sugo"] nbAttr = len(attributes) # Number of attributes support = [[0 for i in range(nbAttr)] for k in range(nbAttr)] confidence = [[0 for i in range(nbAttr)] for k in range(nbAttr)] ''' premises | ------------------------------------- v | 0: | 1: | 2: | 3: | 4: | 5: | <- conclusions ------------------------------------- 0: | | | | | | | ------------------------------------- 1: | | | | | | | ------------------------------------- 2: | | | | | | | ------------------------------------ 3: | | | | | | | ------------------------------------- 4: | | | | | | | ------------------------------------ 5: | | | | | | | ------------------------------------- ''' for sample in X: for premise in range(nbAttr): if sample[premise] == 0: # no premise continue support[premise][premise] += 1 # total of premise item for conclusion in range(nbAttr): if premise == conclusion: continue if sample[conclusion] == 1: # This person also bought the conclusion item support[premise][conclusion] += 1 print "Support:" pprint(support) # Calculate confidence for premise in range(nbAttr): for conclusion in range(nbAttr): if premise == conclusion: continue v = support[premise][conclusion] t = support[premise][premise] if t != 0: confidence[premise][conclusion] = round(v / t, 2) print "Confidence" pprint(confidence) # print result for premise in range(nbAttr): for conclusion in range(nbAttr): if premise == conclusion: continue printRule() Typisches Resultat: Support: Bemerkungen: |
|
|
Visualisierung der Resultate |
|
Einmal mehr veranschaulichen wir die Resultate mit einer gefälligen Visualisierung. Es wird wie üblich das Modul gpanel (für TigerJython), bzw. pygpanel (für Python 2.7) eingesetzt. Programm: [►] # Shopping3.py from gpanel import * datafile = "shopping.dat" def loadIntData(fileName): fData = open(fileName, 'r') out = [] for line in fData: li = [int(i) for i in line.split(',')] out.append(li) fData.close() return out def showGrid(): image("index.png", 0, 470) for i in range(nbAttr + 2): line(80 * i, 0, 80 * i, 560) for i in range(nbAttr + 2): line(0, 80 * i, 560, 80 * i) X = loadIntData(datafile) attributes = ["bread", "cheese", "apple", "banana", "pasta", "sugo"] nbAttr = len(attributes) # Number of attributes support = [[0 for i in range(nbAttr)] for k in range(nbAttr)] confidence = [[0 for i in range(nbAttr)] for k in range(nbAttr)] for sample in X: for premise in range(nbAttr): if sample[premise] == 0: # no premise continue support[premise][premise] += 1 # total of premise item for conclusion in range(nbAttr): if premise == conclusion: continue if sample[conclusion] == 1: # This person also bought the conclusion item support[premise][conclusion] += 1 # Calculate confidence for premise in range(nbAttr): for conclusion in range(nbAttr): if premise == conclusion: continue v = support[premise][conclusion] t = support[premise][premise] if t != 0: confidence[premise][conclusion] = round(v / t, 2) # show result makeGPanel(Size(560, 560)) window(0, 560, 0, 560) title("Number Of Purchases: " + str(len(X))) # show images for i in range(nbAttr): image(attributes[i] + ".png", 0, 400 - 80 * i) for k in range(nbAttr): image(attributes[k] + ".png", 80 * k + 80, 480) showGrid() for i in range(nbAttr): for k in range(nbAttr): if i != k: text(80 * (k + 1) + 30, 400 - 80 * i + 45, str(support[i][k])) text(80 * (k + 1) + 30, 400 - 80 * i + 25, str(confidence[i][k])) else: text(80 * (i + 1) + 30, 400 - 80 * i + 35, "(" + str(support[i][i]) + ")") keep() Typisches Resultat:
|
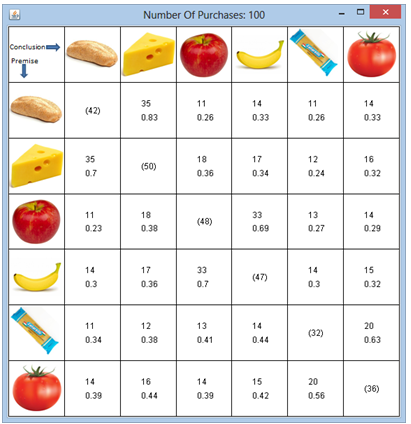
|
|
Sortierte Darstellung |
|
Um mit einem Blick darzustellen, welche Affinitäten besonders hoch sind, können die Konklusionen in der Reihenfolge ihrer Konfidenzen angezeigt werden. Programm: [►] # Shopping4.py from gpanel import * datafile = "shopping.dat" def loadIntData(fileName): fData = open(fileName, 'r') out = [] for line in fData: li = [int(i) for i in line.split(',')] out.append(li) fData.close() return out def showGrid(): for i in range(nbAttr + 1): line(80 * i, 0, 80 * i, 480) for i in range(nbAttr + 1): line(0, 80 * i, 480, 80 * i) lineWidth(4) line(80, 0, 80, 480) X = loadIntData(datafile) attributes = ["bread", "cheese", "apple", "banana", "pasta", "sugo"] nbAttr = len(attributes) # Number of attributes support = [[0 for i in range(nbAttr)] for k in range(nbAttr)] confidence = [[0 for i in range(nbAttr)] for k in range(nbAttr)] for sample in X: for premise in range(nbAttr): if sample[premise] == 0: # no premise continue support[premise][premise] += 1 # total of premise item for conclusion in range(nbAttr): if premise == conclusion: continue if sample[conclusion] == 1: # This person also bought the conclusion item support[premise][conclusion] += 1 # Calculate confidence for premise in range(nbAttr): for conclusion in range(nbAttr): if premise == conclusion: continue v = support[premise][conclusion] t = support[premise][premise] if t != 0: confidence[premise][conclusion] = round(v / t, 2) # show result makeGPanel(Size(480, 480)) window(0, 480, 0, 480) title("Affinity Order") for i in range(nbAttr): image(attributes[i] + ".png", 0, 400 - 80 * i) for i in range(nbAttr): di = {} # dictionary: index:value for k in range(nbAttr): if k != i: di[k] = confidence[i][k] # insert element sortedConclusions = sorted(di, key = di.get) # sort by value sortedConclusions.reverse() # largest first for k in range(nbAttr - 1): image(attributes[sortedConclusions[k]] + ".png", 80 * k + 80, 400 - 80 * i) text(80 * (k + 1) + 5, 402 - 80 * i, \ str(confidence[i][sortedConclusions[k]])) showGrid() keep() # for pygpanel Typisches Resultat:
Bemerkungen:
|
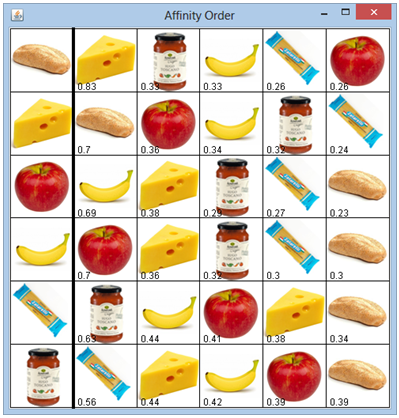
|
|
Warenkorb interaktiv erstellen |
|
Um Einkäufe nach eigenem Geschmack zu tätigen und einer Datesammlung zu speichern, kann wiederum eine anspruchsvolle Grafik angeboten werden, wo man die Produkte mit einem Mausklick in den Einkaufskorb legt und nach maximal 6 verschiedenen Produkten an der Kasse auscheckt. Programm: [►] # Purchase.py #from gpanel import * from pygpanel import * dataFile = "samples.dat" def onMousePressed(x, y): global nbItems, purchase item = (int)(x // 80) if item < n: if purchase[item] == 0: purchase[item] = 1 title("Item " + attributes[item] + " added to basket. Total: " + str(purchase.count(1))) else: title("Item " + attributes[item] + " already in basket. Total: " + str(purchase.count(1))) else: nbItems = purchase.count(1) title ("Checked out with " + str(nbItems) + " items") if nbItems > 0: fOut = open(dataFile, "a") sample = ','.join(str(e) for e in purchase) fOut.write(sample + "\n") fOut.close() purchase = [0] * n attributes = ["bread", "cheese", "apple", "banana", "pasta", "sugo"] n = 6 purchase = [0] * n makeGPanel(Size(560, 80), mousePressed = onMousePressed) title("Click maximal 6 items and check out") window(0, 560, 0, 560) for i in range(n): image(attributes[i] + ".png", 80 * i, 0) image("checkout.png", 480, 0) keep() Programmcode markieren
Tätige deine Einkäufe!
|
