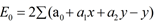| Python exemplarisch |
(Shoppinglisten) Recommender Systeme
(Filmempfehlungen) Klassifizierung
(KNN Algorithmus) Mustererkennung
(Ziffern) Regressionsanalyse
(Wiederverkaufswert) Clusteranalyse
(Voronoi-Diagramm) OneR-Algorithmus
(Wettervorhersage) Neuronale Netze
(In Vorbereitung)
Regressionsanalyse
![]()
|
Alle Programme können von hier heruntergeladen werden. |
|
|
Problembeschreibung |
|
Bei der Regressionsanalyse studiert man, wie eine bestimmte Grösse (ein Ausgabewert) mit anderen variablen Grössen (Eingabewerten) zusammenhängt, beispielsweise der Wiederverkaufswert z eines bestimmten Autotyps vom Alter x und Kilometerstand y. Dabei versucht man, den Ausgabewert z in eine eindeutige Beziehung zu den Eingabegrössen x, y zu bringen, mathematisch ausgedrückt, eine Funktion z = f(x, y) mit zwei Variablen x, y zu finden, welche den Wiederverkaufswert "am besten" wiedergibt. |
|
|
Eindimensionale lineare Regression |
|
m einfachsten Fall hat die Funktion nur eine einzige Variablen x und die Beziehung eine lineare Funktion y = f(x) = a * x + b mit den zwei Parametern a und b. Die Funktion kann als Gerade in einem x-y-Koordinatensystem dargestellt werden. Ausgehend von einem Trainigs-Set stellen wir uns die Aufgabe, die Parameter optimal zu bestimmen. Was versteht man darunter? Wir betrachten ein Beispiel: Die Trainigs-Daten sind als sechs [x, y]-Wertepaare gegeben und werden in einer Liste X zusammengefasst. X = [[1, 2], [3, 3], [4, 5], [5, 6], [6, 5], [8, 7]] Wir können sie als Punkte in einem GPanel einzeichnen, wobei wir zur besseren Sichtbarkeit kleine Kreise zeichnen. Programm: [►] # Regression1.py from gpanel import * samples = [[1, 2], [3, 3], [4, 5], [5, 6], [6, 5], [8, 7]] def drawData(): for sample in samples: pos(sample) fillCircle(0.07) makeGPanel(-1, 11, -1, 11, mousePressed = onMousePressed) drawGrid(0, 10, 0, 10, "gray") title("Data Points") drawData()
Bemerkungen: |
|
|
Optimale Funktion -> Kleinste Fehlersumme |
|
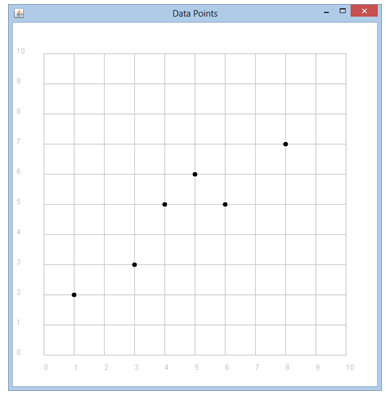
Denken wir, dass die beiden Parameter a (Steigung) und b (Offset) einen bestimmten Wert haben: a = 0.5, b = 3 und tragen wir die Gerade z = f(x) = 0.5 * x + 3 im Koordinatensystem ein. Diese Gerade ist offenbar eine schlechte Näherung für die gegebenen Datenpunkte, da sie weit daneben verläuft. Zu jedem Datenpunkt können wir einen Fehlerwert e als vertikalen Abstand des Datenpunkts von der Gerade angeben: e = abs(f(x) - y). Programm: [►] # Regression2.py from gpanel import * samples = [[1, 2], [3, 3], [4, 5], [5, 6], [6, 5], [8, 7]] a = 0.5 b = 3 def f(x): return a * x + b def drawData(): for sample in samples: pos(sample) fillCircle(0.07) def drawLine(): line(0, f(0), 10, f(10)) def showErrors(): errorSum = 0 setColor("red") for sample in samples: x = sample[0] y = sample[1] e = abs(y - f(x)) errorSum += e line(x, y, x, f(x)) text(x + 0.1, y, str(e)) return errorSum makeGPanel(-1, 11, -1, 11, mousePressed = onMousePressed) drawGrid(0, 10, 0, 10, "gray") title("Data Points") lineWidth(2) drawData() drawLine() E = showErrors() title("Error sum: " + str(E))
Bemerkungen: |
|
|
Multidimensionale lineare Regression |
|
Wir packen nun das eingangs erwähnte Problem an, eine Voraussage über den Wiederverkaufswert von Autos zu machen. Davon gehen wir von folgendem Trainings-Set aus.
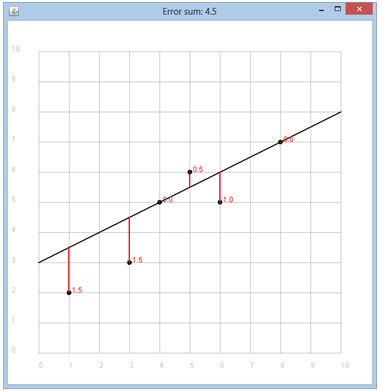
Wir machen einen linearen Modellansatz: z = f(x, y) = a0 + a1* x + a2 * y, wo x das Alter, y der KM-Stand und z der Verkaufspreis sind. Die Parameter a0, a1, a2 müssen mit dem Regressionsverfahren optimal angepasst werden (a0 entspricht dem Neuwert, a1 und a2 sind sicher negativ). Die Fehlersumme und die Ableitungen nach den drei Parametern lauten:
Wir gehen wie oben schrittweise vor und schreiben immer nach 10'000 Iterationen die Parameter und die Fehlersumme aus. Nach 50'000 Iteration ist die Konvergenz gut genug und wir können den voraussichtlichen Occasionspreis eines siebenjährigen Autos mit einem Kilometerstand von 60'000 km bestimmen. Programm: [►] # Regression4.py import time # Set of samples [x1, x2, y] # Used car price [years, km /1000, price SFr/1000] samples = [[5, 57, 8.5], [4, 40, 10.3], [6, 77, 7], [5, 60, 8.2], [5, 49, 8.9], [5, 47, 9.8], [6, 58, 6.6], [6, 39, 9.5], [2, 8, 16.9], [7, 69, 7], [7, 89, 4.8]] # Iteration step in both directions ds = 0.00001 def f(x1, x2): return a1*x1 + a2*x2 + a0 def error(): e = 0 for sample in samples: de = (f(sample[0], sample[1]) - sample[2])**2 e += de return e def gradient_a1(): # Derivative with respect to a1 s = 0 for sample in samples: x1i = sample[0] x2i = sample[1] yi = sample[2] s += (f(x1i, x2i) - yi) * x1i return 2 * s def gradient_a2(): # Derivative with respect to a2 s = 0 for sample in samples: x1i = sample[0] x2i = sample[1] yi = sample[2] s += (f(x1i, x2i) - yi) * x2i return 2 * s def gradient_a0(): # Derivative with respect to a0 s = 0 for sample in samples: x1i = sample[0] x2i = sample[1] yi = sample[2] s += (f(x1i, x2i) - yi) return 2 * s # Start values a1 = 0 a2 = 0 a0 = 0 iterationNb = 0 print "Learning now. Please wait..." for i in range(500000): iterationNb += 1 a1new = a1 - ds * gradient_a1() # descent in a1 direction a2new = a2 - ds * gradient_a2() # descent in a2 direction a0new = a0 - ds * gradient_a0() # descent in a0 direction # updata a1, a2, a0 a1 = a1new a2 = a2new a0 = a0new if iterationNb % 100000 == 0: print "%3d iters-> a1 a2 a0: %4.2f %4.2f %4.2f -- Error: %4.2f " \ %(iterationNb, a1, a2, a0, error()) print "Learning process terminated" print "Prediction for a 7-years old car with 60'000 km:", \ int(1000 * f(7, 60)), "SFr" Resultat: Bemerkungen: |